Understanding PTV xServer scaling behaviour and getting tips for tuning is relevant for you if one or more of the following points is true:
you operate or are planning to operate a cluster of more than one PTV xServer machines
your perceived performance is not satisfactory or you require a very good user experience
you have (hard or soft) real time requirements
your system is often busy, or you expect a high load
Basic Terminology
Response Time
The response time is the duration of a PTV xServer transaction, in the case of a simple transaction this is the time between request sending and response arrival.
Minimal response times are very important for a good user experience, especially for interactive uses.
Because of proxies the server might not be able to observe and log the client's response time but a shorter period:
The server can only observe the communication start and end with the "nearest" proxy.
Due to latency, the first parts of the requests and the last parts of the response may still be en route from or to the client.
Throughput
The throughput is a metric for the maximum load capacity of your server. It is measured as the number of completed transactions over time.
Maximal throughput is very important for mass use scenarios, especially batch processing.
Load
The system load is a measure for the work the system has to perform, usually in the form of CPU activity.
The service load is a more abstract measure and corresponds to the transaction arrival rate.
A higher service load will cause an increase of system load. If the system load reaches 100%, response times will start to degrade but
throughput starts to peak. Transactions have to wait and may have to be rejected: the system is then overloaded.
Benefits
Scaling your PTV xServer cluster properly and optimising it will:
increase user satisfaction by improving the level of service
minimise hardware requirements by utilising the hardware to the fullest
In order to achieve an optimally tuned system you will have to do your own measurements.
PTV's reference benchmarks only give an indication of performance - numbers are valid for a given configuration and a given test set only.
Your configuration and your requests will not be identical, and neither will be your performance numbers.
Optimization Goals
There is not one obvious optimization goal, but two: minimise response times, and maximise throughput.
To minimise response times it is necessary to maximise hardware availability. This may mean that the system is often idle.
To maximise throughput it is necessary to maximise hardware utilisation. This may mean that transactions sometimes have to wait.
Throughput and response times could only be optimal at the same time if requests arrive precisely when a response has been sent:
no requests have to wait, and all workers can be active at all times. This is not only improbable but because of the inherent latency times
involved it is also impossible.
It is however possible to strive for minimal response times until the system load becomes so high that available computing resources no
longer allow to maintain this optimum. Then ones strive for maximum throughput to avoid loss of service: accepting a performance degradation
is usually better than rejecting service requests. This optimization goal does not conflict with the mass use scenario where response times
are secondary concerns: smaller response times will also increase throughput, and during periods of low load neither response times nor throughput are compromised.
The Role of the Operating System
The choice of the operating system has a certain influence on performance.
Regardless of the choice of operating system, there are a couple of mechanisms that are especially important for PTV xServer performance.
Under Windows Server operating systems, make sure energy saving mode is set to “high performance”, not the factory default.
For the choice of operating system, performance will differ between versions, and also between platforms.
The difference between platforms stems mostly from compilers.
The advantages shift with compiler versions and options, and transaction types as well.
Linux tends to have more robust file systems which rarely, if ever, block.
File Caching
Modern operating systems do not let "free" main memory left unused but use it to cache files.
Access to cached files is massively faster than disk accesses and only slightly slower than direct memory access.
These caches are only observable with specialised tools.
Since PTV xServer access map data using memory mapped files, file caches are fairly important and having sufficient free RAM is beneficial.
The exact effects vary. As the operating system will attempt to keep the most frequently and most recently used files cached, the performance
gains will usually diminish fast as the "hot zones" of the map files are kept in RAM anyway.
PTV xServer can run just fine with one GiB of "free" RAM but depending on your request mix it can profit from more, up to roughly the total
size of all map files, as long as all parts of the map are regularly accessed.
Hyper-Threading
Modern operating systems assign processes to physical cores first, then use the so-called virtual cores.
Thus, hyper-threading will not slow down your system when there is little load.
As a consequence, all cores can and should be used.
Active virtual cores will not decrease response times while they do not have to be used but increase throughput when they are needed.
Background Processes
Operating systems assign CPUs to processes as they need execution.
Letting processes remain idle for long periods does not impact the busy ones in any significant way as long as they can be kept in memory -
otherwise I/O is required before the process can become busy.
As a consequence, given sufficient RAM you can start many more processes than you have CPU cores to execute without a noticeably loss of performance.
Some deployment strategies can benefit from such a scenario.
Deployment Guide
Before you plan your deployment you need to understand the requirements: what service APIs do you need, what capacity,
responsiveness, availability.
From these you can derive the overall amount of worker processes. After deciding the type of server hardware you can then plan the
per-server deployment to find out how many hardware units you need in your server cluster.
Determine Required Overall Throughput
The first step is finding the required overall capacity for your system, in terms of overall throughput.
For batch processing scenarios, the required throughput is usually already given (e.g. 100 tours to plan in one hour).
For interactive uses, the number of users and number of concurrently active users can be estimated, the number of
triggered transactions per user can be roughly estimated (the Poisson distribution may be a helpful model) but is best determined
from logs of field tests or actual uses. Make sure you chose a suitably short time interval when measuring user transactions -
requests per hour is not a suitable scale, requests per minute or second are better indicators for the capacity required to provide
not only throughput but good response times as well.
Also, you should plan with Winsorised results or an upper quantile (e.g. 90%) plus a buffer depending on
the quality of service you want to provide at peak use times as well as the confidence you have in your estimations.
The required overall throughput has to be determined per service type. Distribution over all request types is also a useful
information when deciding how much overlap is tolerable when mixing services (more on that later).
If several different usage scenarios are combined, you can either use dedicated clusters or setup one cluster that can handle all of the load.
Dedicated clusters protect other clusters from overload situations, e.g. long running requests blocking all the workers, leaving no one for the short requests.
A shared cluster on the other hand can better balance out peak load.
As an initial guess for the number of workers required you can measure or extrapolate the throughput of one worker process
from the test run results. While the real throughput numbers depend on the final hardware as well as the final deployment, the
initial guess helps to select the type of servers required.
Dimensioning Servers
How much throughput a single server has, how many servers you need, and how to ideally set it up depends on your server type.
By now you have an idea about the number of processes you must run, and what type of server you are looking for.
If you have a lot of processing to do, using fewer but larger servers is usually more cost effective:
pro: you can make better use of your RAM
pro: you can make use of synergy effects (cache usage, hyper-threading) when mixing services
pro: you save energy
pro: you need less hosting space
pro: you save efforts in administration
con: redundancy can be more costly (e.g. for "four nines" availability you may need 2 backup servers if you require 3 for operations - 40% of your servers are redundant,
while you would only need 3 backup servers if you require 6 for operations - 33% of your servers are redundant)
con: if you need only a little bit more capacity you either have to begin mixing server types or increase capacity
only by a larger amount, both of which can increase costs
Once you have selected a cost efficient server type, you know the number of CPU cores per server.
Sizing Server Worker Pools
To obtain the number of servers required you need to determine the optimum number of worker processes per server.
The pool size per server only scales the worker processes which are responsible for the actual computation.
The web server also produces CPU load, primarily during (de)serialisation.
This overhead varies between requests, typically between 1 (very long running requests)
and 50% (very short and small requests).
Worker processes that have to wait before they get CPU access do not improve throughput; cache thrashing effects can even bring it down.
As a consequence, there is a maximum effective pool size for a given request mix. The maximum effective pool size is
smaller than the number of (virtual) CPU cores - how much smaller depends on the server overhead percentage.
Any larger pool size will not increase the reachable throughout.
Similarly, there is a maximum efficient pool size which is smaller than the number of physical CPU cores.
If more workers need to be active, hyper-threading becomes activated and response times will increase.
You need to determine the maximum effective pool size with your own hardware and test sets if you want to fully optimise
your deployment. You can start with the number of virtual CPU cores (or a bit less depending on the type of server), then
remove one worker after another until you see a noticeable decrease in throughput. The larger number is then the maximum
effective pool size.
When in doubt about the maximum effective pool size, round up. There are no issues when using a few more
workers but there might be benefits: unexpected sequences of long running requests would profit from more workers as
the maximum effective pool size would be larger than expected during that period.
Also, a small amount of redundancy on a per-server basis can better bridge
the time until a replacement process is started after one crashes - which does not occur often, of course.
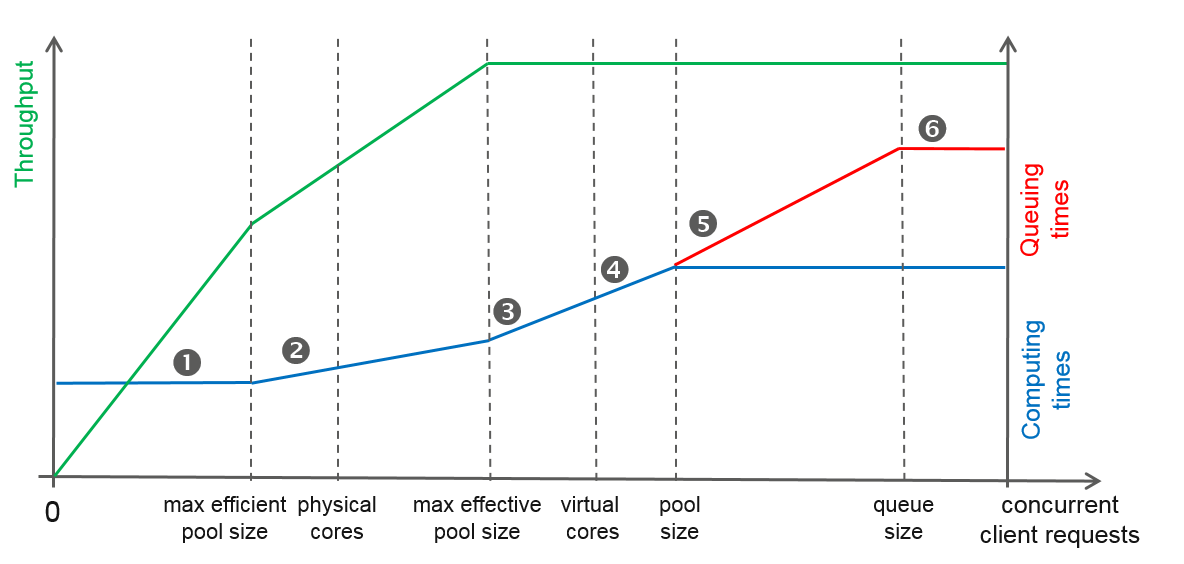
The properties of hyper-threading and the web server threads lead to a characteristic scaling curve of PTV xServer,
illustrated in the chart below. In the real world, this curve is a bit wobbly due to measurement inaccuracies, and also
more rounded.
The chart shows major response time components as well as reachable throughput depending on the number of concurrent client
requests. Several relevant stages are marked, under the assumption that the actual pool size is set above the number of virtual
cores; this configuration is for illustration only, not the goal. For practical purposes you should set the worker pool size to the
maximum effective pool size, but not exceed the number of virtual cores.
under low load, response times are minimal and the throughput increases linearly
when the maximum efficient pool size is reached, worker processes will have to be assigned to virtual cores already;
the physical cores are already running with other workers or server threads
until the maximum effective pool size is reached, worker processes and server threads share cores but every thread
is still executed in parallel; throughput still increases while average response times become slightly worse (due to execution
pipeline conflicts during hyper-threading)
when the maximum effective pool size is surpassed, response times become much worse; while more transactions are processed
concurrently, overall throughput now stagnates as worker processes and server threads have to compete for all CPU cores
when the set pool size is surpassed, there are more transactions than workers and additional transactions have to be queued;
response times continue to get worse, this time due to queue waiting times
finally, when there are more active transactions than workers plus queue slots, additional transactions are rejected;
this prevents other clients from overly long response times and the server from memory overflows
Even under full load it is hard for the scheduler to keep all workers busy all the time. There is a certain overhead involved
when swapping workers - after sending the result to the server worker processes are idle until they are fed (or they can fetch)
the next request.
With old PTV xServer schedulers, the maximum effective pool size was larger than the number of cores available.
"Overbooking" a system with more processes was effective since the scheduling latencies could be hidden with sufficient worker
processes: if one process is idle, another one can make use of the CPU.
New PTV xServer schedulers are better optimised, the scheduling overhead is so low that overbooking your CPU with additional
worker processes for a given service no longer is effective.
Combining different services per server is an option if
you have sufficient RAM for all worker processes
you can accept longer start-up times for your servers
you can accept updates of all machines even when you need only an update for one individual service
In this case, you gain the following advantages:
better average utilisation of your CPUs - less idle times as there is more often a process that can use a CPU core;
hence, you need less overall machines to handle your request mix
better utilisation of your RAM - services access the same map files, file caching works across processes and services
less effort for administration: setup is equal for all machines (also simplifies load balancing etc.)
better use of caches (synergy effect)
better use of processor pipeline sharing during hyper-threading (synergy effect)
If you deploy mixed services, you usually need less overall servers. It is highly likely that you need the full throughput
for all services at the same time; instead, a transaction chain of a client tends to hop between services: first geocode addresses,
then calculate a route, then show the result on the map.
A heterogeneous cluster will only be efficient when the actual transaction mix precisely matches the estimated distribution
and overlaps at some time.
If you are willing to spend the same amount of machines for a homogeneous setup as you would need for a heterogeneous
setup, you would still profit. The homogeneous setup can handle ANY transaction mix that does not surpass the maximum of all
services while the heterogeneous setup can only handle its particular distribution.
Also, you need less backup machines for the homogeneous setup since all machines can serve as backups for each other.
Server Cluster Setup
Now that the number of workers required per service is determined, server hardware has been chosen, the maximum effective
pool size has been measured and the deployment of workers in the cluster is defined, the actual number of server machines
for the cluster is available.
PTV xServer cannot distribute transactions between themselves, they need an external component to do it for them, a web proxy
acting as load balancer.
The default strategy for load balancing software is usually Round Robin, simply cycling through servers.
This strategy works well for short requests without much variation in response times, e.g. the delivery of HTML pages.
However, if response times vary a lot, this strategy might congest servers, e.g. assigning all long running requests on one server
by accident. Such congestions become less likely when servers have a larger pool size.
For PTV xServer clusters with a mix of services deployed, the Round Robin strategy is not recommended.
The Connection Counting strategy attempts to level the number of active HTTP connections.
This strategy works well for requests that allocate comparable amounts of computing resources (mostly CPU cores).
However, if allocated resources (mostly CPU cores) vary a lot this strategy might congest servers.
For PTV xServer clusters that are set up for the asynchronous protocol, active HTTP connections do no longer indicate actual CPU
usage and the Connection Counting strategy is not recommended.
The Load Probing strategy attempts to level CPU load. For this, the load balancer has to query servers periodically.
This strategy works well for requests that primarily use CPU as resource. This strategy is suitable for all uses of PTV xServer.
Cost-free proxies that provide Load Probing are Apache httpd (with mod_cluster add-on),
or Microsoft IIS (with Server Feedback Agents). Commercial load balancers usually also support this strategy.
Middleware and network infrastructure all negatively impact communication times.
To decrease latencies you should attempt to minimise the number of hops for your HTTP messages.
Attempt to use only one extra level of web proxies.
Host your application middleware in close proximity to PTV xServer: local host would be as close as you can get,
sharing the same local network is next best, sharing the same hosting center is third choice.
If you generate lots of traffic, ensure your network bandwidth has not become a bottleneck.
If you are using the asynchronous protocol or wish to store your own POI you have to use one central database so that
every server in the cluster has access to consistent data.
A central database also can make better use of caches as all queries go to one system.
If you are using a central database or you plan to query POIs a lot you should consider a dedicated database server.
Then, your database will not compete for CPU with the web server or worker processes, and your database can profit a lot more
from fast I/O.
Your measurements and calculations until now have gotten you the number of required servers.
There is still one concern that impacts scaling: your required service availability.
You need some more extra backup systems for your servers.
The cumulative binomial distribution function can tell you the minimum number of backup units for your targeted availability:
The availability A for a set of n exchangeable units with individual availability a of which you need at least k units to work is:
A = Σi=k..n(ni) ai (1-a)(n-i).
A "unit" can refer to servers, processes, databases, hard drives, network switches, and so on. For the model to work, you need to know or guess the availability of an individual unit.
For instance, modern server boards come with built-in redundancy measures and achieve an overall hardware availability of about 99% ("two nines"). Standard office workstations typically
reach 97 to 98% availability .
If you need at least
units for your work load, and you assume an individual availability of
%, you require a total of 4 / 5 / 6 units in order to achieve an overall availability of 99.7664% / 99.9922% / 99.9998%.
If backup systems are also operational ("hot standby") you also gain a capacity reserve as long as there are no failures.
However, it is important not to rely on this extra capacity for standard operations - otherwise the redundancy systems are no longer redundant.
PTV xServer perform fairly well in virtualised environments: they do not depend on fast I/O which tend to suffer from virtualisation overhead.
Virtual environments bring a lot of benefits:
facilitate staged rollouts (swapping between clusters works nearly instantaneously and seamlessly)
allows to shift resources and control costs (redeployment on different hardware is not hard, reconfiguring is not hard)
allows to activate cold stand-by systems quickly
facilitates certain tests (traffic shaping, simulate less hardware, test with different operating systems/versions)
built-in surveillance
Of course, you need to familiarise yourself with the host software and might have to pay licenses.
In cloud environments (which you can think of as a virtualised environments with as many extra servers as you are willing to pay)
you may be able to scale up your cluster even after the initial setup, simply by adding further virtual machines to your cluster.
This process can even be automated (so-called "elasticity") depending on a schedule or on the current load.
Programming Guide
There are some dedicated programming tasks involved in scaling and tuning PTV xServer.
First, you need to measure the performance to validate your tuning efforts.
Second, you need to make sure that clients use the carefully planned cluster properly.
Proper Benchmarking
Doing your own benchmarks is a central point of your optimization efforts. Doing correct measurements is not complicated,
but measuring the correct things can be. You should avoid the following pitfalls.
Do not run your benchmark clients on the server you measure.
Do not measure the warm-up: run your test suite more than once and ignore results from the first run.
Measure a scenario that actually utilises all of your CPUs. Systems behave differently when stressed.
To measure response times, your queue must be empty: number of concurrent transactions = pool size
To measure throughput, your queue must not be empty: pool size « number of concurrent transactions = queue size
Do not measure your network bandwidth by accident.
Do not measure your proxy settings by accident.
Do not measure your local hard drive performance by accident. Make sure you measure with the correct logging settings.
If you avoid the pitfalls above, obtaining correct results is not too hard.
Client Optimization Tips
Your client code can also impact performance. The following sections give you some important tips.
Only request attributes that you intend to use. Optional attributes all take time to convert, compute, look up,
serialise and transmit. After you have explored all features of PTV xServer, make sure you strip down your requested options
to those you really need.
If you have the choice between SOAP and JSON formats, chose the one you are more familiar with.
The serialisation format has little impact on performance (˜~2% communication time in favour of JSON).
Whenever your PTV xServer requests leave the local network, have your client accept
compressed HTTP responses.
Compression costs some CPU cycles but reduces communication times.
This can even be a good idea within local networks in order to save bandwidth.
If you use parallel transactions you need to send HTTP requests asynchronously; that means separate threads.
The mechanisms for this depend on your programming language. In Javascript, this is done for you automatically - the
HTTP communication is done for you and you receive a callback when it is done. In Java or C# you would need to spawn your own
thread.
Even if you need only serial transactions you should not block your client code waiting for a HTTP response.
While this has no actual impact on response times, a non-blocking client has a better performance as perceived by the user.
Do not confuse asynchronous requests with the asynchronous server protocol. The asynchronicity is not the same:
the asynchronous request is handled by the client exclusively, while the server drives the asynchronous protocol.
Of course, you can combine both: use asynchronous requests for the asynchronous protocol.
You can help most PTV xServer by limiting the search space. For instance, you can define countries in geocoding or
routing boundaries, if applicable (e.g. city routing scenarios).
The fastest transactions is the one you do not need. There are some cases where (extra) transactions can be avoided.
Use the bulk request variants of operations whenever applicable. The bulk versions save a lot of communication overhead
and can make much better use of processor caches. They usually provide speedups between 2 to 5 when compared to a sequence
of single transactions.
Users can make requests obsolete by their actions: zooming the map makes pending requests for tiles obsolete,
pressing a key makes previous search suggestions obsolete. You should "debounce" such transactions: Send requests only a short while
after the last user action. If you send multiple requests, use a queue that you can reset.
If you have batch processing to do, send requests in parallel, even exceeding the overall pool size of your cluster, but never
the queue size of one server.
If you do not saturate the servers, they will have to wait for clients and have idle times.
Of course, queueing times will prolong individual response times, but you will gain overall throughput.
If latency makes up around 50% of response time, send twice the number of requests concurrently; then, the server can compute one response while the next request is transferred.
Adjust this factor according to your actual communication time overhead.
If you do not have a dedicated cluster, only apply this technique in a limited way, in order to leave sufficient server
capacity for other users.
This technique is especially notorious to produce network bandwidth issues. Monitor your bandwidth usage.
In heavy duty mass data applications the client also has to scale. If you do not generate requests fast enough, the server
cluster will remain idle.
You can generate HTTP requests faster if you send requests in raw form. It is feasible to generate the HTTP requests manually
and generate the message bodies by using a XML or JSON text template and filling out the variable parts. This is faster than the
object serialisation necessary with generated or bundled clients. Of course, maintenance of these templates will take more effort
as the first class objects of the clients are much more convenient to use.