Basically the clustering partitions the visits of customers into different groups (clusters). In doing so every visit is assigned to exactly one cluster.
The use case planClusters is the simplest way of planning clusters. Given is an amount of orders. An order contains one visit. The cluster optimisation groups these visits into a given number of clusters assigning every visit to exactly one cluster. Thus the clustering performs a partitioning of the visits into disjoint sets of visits.
The following figure shows an example with 18 orders and hence 18 visits partitioned into 4 clusters.
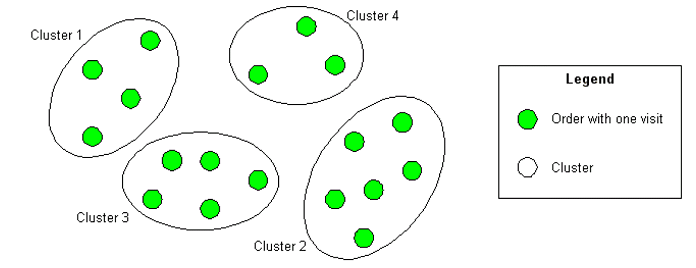
The use case planWeek plans the visits for one week. Given is an amount of orders. An order contains one or more visits within that week. Thereby all visits of an order have the same location and follow specified weekday patterns (e.g. in the case of two visit Monday-Wednesday or Tuesday-Friday). The cluster optimisation groups these visits into the given weekdays assigning every visit to exactly one weekday.
The following figure shows an example with 22 orders and 24 visits partitioned into 5 weekdays.
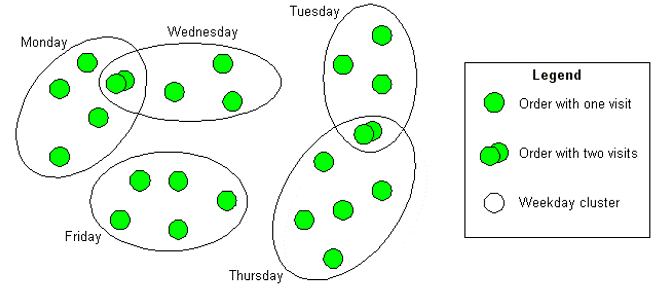
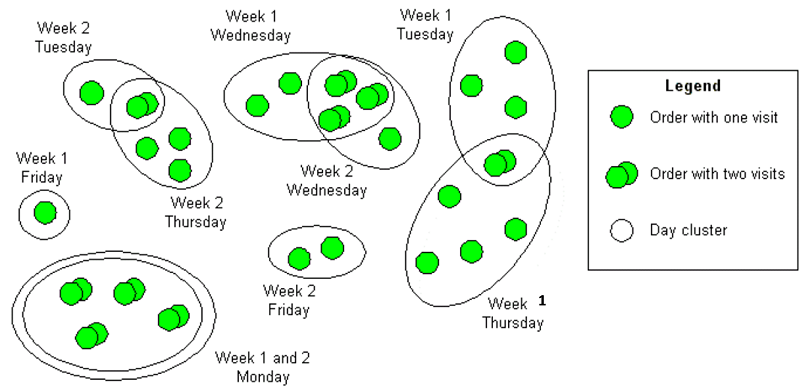
The use case planMultiWeeks plans the visits for more than one week. Given is an amount of orders. An order contains one or more visits within that weeks. Thereby all visits of an order have the same location and follow specified week rhythms (e.g. every week or biweekly) and within a week specified weekday patterns. The cluster optimisation groups these visits into the given weeks and weekdays assigning every visit to exactly one day. Every day correspond to one cluster.
The following figure shows an example with 26 orders and 35 visits partitioned into 2 weeks each with 5 weekdays.
Please consult the this chapter for general information on jobs.
The service methods planClusters, planWeek, and planMultiWeeks have corresponding start-methods startPlanClusters, startPlanWeek, and startPlanMultiWeeks to start the calculation as a job. The corresponding fetch-methods are fetchClusterPlan, fetchWeekPlan, and fetchMultiWeeksPlan.
During the calculation the current calculation progress can be watched using watchJob. This method returns an instance of ClusterProgress which contains information on which action is currently being executed. The action attribute contains one of the following values.
| Action | Description |
|---|---|
| Import | The request data is being imported. |
| DistanceMatrix.Preparation | The distance matrix calculation is being prepared which comprises amongst others linking the co-ordinates to the routing network. |
| DistanceMatrix.Calculation | The distance matrix is being calculated. For this action the calculation progress will be returned in ClusterProgress. The final progress information will be preserved for the next steps to denote that distance matrix calculation has been finished. |
| Optimization.Initialization | The initialisation step is being executed. In case of executing the following construction step all visits get a new first assignment. In case of omitting the construction step only the visits without an imported cluster assignment get a new first assignment. Thereby the objectives compactness and distribution are not considered. After this step all visits are assigned to a cluster. |
| Optimization.Construction | The construction step is being executed. It tries to relocate the visits to another cluster to build the clusters as compact as possible. The objective distribution is not considered. |
| Optimization.Improvement | The improvement step of the optimization is being executed. This is probably the most time-consuming action which tries to relocate the visits to another cluster to improve the objective distribution and at the same time not to worsen the objective compactness crucially. |
| Optimization.PostOptimization | The post optimisation step is being executed which tries to swap two visits from different clusters to improve the objective compactness. As these two visits must have the same quantity, the objective distribution remains unchanged. During this step only orders with one visit are considered. |
| Export | The resulting plan is exported to the response. |
The order of the action values is shown in the table above.
When stopping the currently running job using stopJob the best plan available at that point of time will be returned by the fetch-method. The stop action may take some time in order to create this plan which will always be valid but not completely optimized.
An exception will be thrown if no intermediate result is available, for example when stopping the request during distance matrix calculation.
By default the distance matrices will be stored in the subfolder data/dima until deleted by request. If need be, this folder can be changed in the file DimaCtrl.ini which can be found in the conf folder.
[Dima] Root=data/dima
Under some circumstances such as a cloud installation it may be necessary to enter a path which is not located on the local machine but somewhere else on the network. This should be done with care as when multiple PTV xServer access the same distance matrix folder access violations may occur, for example when one PTV xServer calculates a distance matrix and another one on a different machine wants to access it. Therefore, subfolders are locked during access using the filesystem. Unfortunately, not all filesystems, especially those for network shares do support this locking feature. Windows or Linux (NFS) shares will be supported when all accessing PTV xServer are installed on the same operating system. Samba shares will not be supported.
If in doubt, check this by calculating a distance matrix on one machine and by deleting it from another machine at the same time. If deleting fails with an access violation which says that the distance matrix is locked, everything should be fine.
Ids of distance matrices have to be unique in the scope of the PTV xTour Server: different users cannot use the same dima id in their requests and re-use their previously calculated distance matrices (DistanceMatrixByReference and DistanceMatrixByRoad). To avoid such id conflicts, the id scope can be made user-specific by setting a tenant name for each user. The tenant name can be provided in two ways:
The header field is meant to be set in a middleware that is responsible for user management, e.g. for PTV xTour Server as a private cloud service. If tenant names are used solely to provide user namespaces, you can use the CallerContext property instead. Both mechanisms can even be combined.
The tenant name is case insensitive and will be prepended to the numerical dima id requested by the user. Alpha-numerical dima ids will only be used internally for folder names of stored distance matrices. In exception messages or progress information, the numerical dima id is used.
Copyright © 2025 PTV Logistics GmbH All rights reserved. | Imprint